Ethvert klik på en hjemmeside, enhver mail, text eller download, alle dine indkøb på nettet, betalinger med dit betalingskort, din brug af Facebook og Twitter. Listen over vores digitale fodspor er uendelig og ingen aner længere hvem, der ved hvad om hvem. Men de indsamlede data bliver brugt.
”På internettet er der ingen, der ved, at du er en hund”. Det er teksten til en berømt tegning af Peter Steiner, der blev offentliggjort i The New Yorker den 5 juli 1993, og som står tilbage som en klassiker fra internettets barndom.

Nu er nettet blevet om ikke voksent, så i hvert fald betydeligt mere smart, og i dag ville alle med det samme vide, at du er en hund.
Det russiske softwarefirma, I-Free, gav med sin ”Girls Around Me”-app fra 2012 et uforglemmeligt bidrag den almindelige folkeoplysning om, hvor meget information om os, der flyder rundt på nettet, og hvordan det er forholdsvis enkelt at indsamle og vise informationerne til alle og enhver.
”Girls Around Me”-app’en, kombinerede Facebook-profiler med GPS-data, og vupti, så kunne appen vise den præcise tilstedeværelse inklusive portrætfotos af de fleste af kvinder (nemlig dem med en tændt iPhone), der befinder sig i samme bydel som dig, og uden at de pågældende kvinder havde nogen anelse om, at de kunne ”ses”.
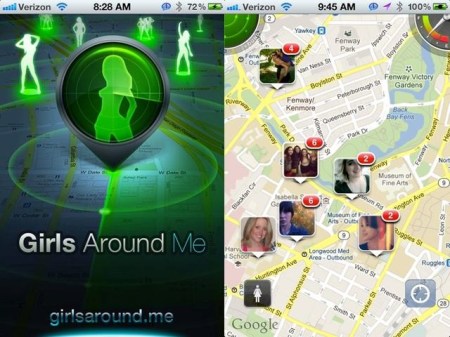
Efter en – meget læseværdig – omtale af app’en på en populær Apple-blog, Cult of Mac, blev ”Girls Around Me” lukket. Men siden 2012 er der sket en revolution i indsamlingen og anvendelsen af persondata på nettet, der får I-Free’s pige-finder app til at ligne en vittighed.
Præcis hvilke persondata, der opsamles på nettet, af hvem, om hvem, hvornår og til hvilket formål, det fortaber sig i tåger, men der hersker ingen tvivl om, at det er store datamængder fra mange kilder, og at der er store penge i disse data og i anvendelsen af dem.
Nogle af verdens største internetfirmaer, som Google og Facebook, har fuldstændig baseret deres forretninger på indsamling og kommerciel anvendelse af data om deres brugere, herunder videresalg til andre virksomheder, der anvender disse data på måder, som hverken Facebook eller Google har nogen viden om eller indflydelse på.
Tilbage i 2006, da Facebook stadig var en forholdsvis lille virksomhed med under 100 ansatte, var forståelsen af dataindsamling og analyse stadig på begynderstadiet. Facebook ansatte derfor nogle af de skrappeste matematikere, som de kunne finde, til at udvikle metoder til at indsamle og analysere brugerdata.
Et af de lyse hoveder var Jeff Hammerbacher, der i nogle år stod i spidsen for Facebooks forskning i brugerdata.
Resultaterne af forskningen gav Facebook den indsigt, som virksomheden skulle bruge, dels for at tiltrække millioner af nye brugere, og dels for efterfølgende at kunne tjene penge på at sælge data til annoncører om brugernes interesser, adfærd og ønsker.
Efter få år forlod Jeff Hammerbacher i frustration Facebook, og forklarede i den forbindelse i et legendarisk interview med BusinessWeek, at han selv og de forskere han samarbejdede med hos Facebook, spildte deres talenter på perspektivløse problemstillinger: ”En hel generation af de klogeste hoveder i USA bruger deres tid og talent på at udtænke, hvordan man kan få flere mennesker til at klikke på en annonce. Det er sygt.”
Men på det tidspunkt var forskningen nået ganske langt, og katten var ude af sækken. Siden er det gået slag i slag, og i dag er indsamling og analyse af data om brugernes adfærd på nettet nået lysår længere, og det samme er Facebooks og Googles indtægter.
Forskningen i analyse af brugerdata bygger blandt andet på en stor database, som over 4 millioner Facebook-brugere har medvirket til at opbygge ved at stille deres egne data til rådighed i anonymiseret form via en app på deres Smartphone.
På grundlag af disse datasæt kan man undersøge forskellige metoder til at analysere data og afprøve mulighederne for at udlede informationer om brugerne ud fra forskellige parametre.

I et stort anlagt studie fra 2012 viste forskere på University of Cambridge, hvordan de på grundlag af Facebook-databasen kunne identificere en række personlige forhold om brugerne med en forholdsvis stor sandsynlighed, alene på grundlag af brugernes uddeling af ”likes”.
Inden for den finansielle sektor er der bestræbelser på at anvende tilsvarende analysemetoder til at vurdere kundernes kreditværdighed, for eksempel baseret på en detaljeret analyse af, hvor en kunde har anvendt sit betalingskort. (Lidt for mange værtshusbesøg og jævnlige ture til galopbanen trækker ned).
Fortalerne for at anvende kundens digitale fodspor til kreditvurdering henviser til, at analysen er objektiv, og at kunderne dermed får en mere ensartet behandling set i forhold til den traditionelle mere subjektive vurdering, der foretages af en medarbejder i en bankfilial.
Skeptikere peger på, at det kan blive meget vanskeligt for en kunde med den forkerte profil at forbedre sin profil, fordi det er uigennemskueligt, hvilke data analysen bygger på. Nogle grupper af kunder kan derfor blive afskåret fra kreditmuligheder på et forkert grundlag, og uden at der er så meget at gøre ved det.
Henvisninger og baggrund: 06-04-2015
